Agent Embeddings
It has been demonstrated that high-dimensional data like images of faces can be compressed into low-dimensional vector representations that are semantically meaningful. For example, here’s an illustration of interpolation within the latent space of two face embeddings in the recent Glow: Generative Flow with Invertible 1×1 Convolutions paper.

It is hard to articulate exactly what a face is, especially to somebody who suffers from severe prosopagnosia. But nonetheless, we can program computers to learn an underlying manifold for faces that can be used to build face detection systems. This is quite remarkable and is a crowning achievement of deep generative modeling.
An often-made criticism in deep learning is that neural networks are uninterpretable. It is hard to articulate why neural networks make the decisions they do. This is especially so for neural network based reinforcement learning agents like DQN.
In a new paper, we propose to make progress towards this problem by learning embeddings for reinforcement learning agents. We collect a huge number of neural network based reinforcement learning agents for a pole-balancing task, vectorize their weights, and learn a generative model over the weight space in a supervised fashion.
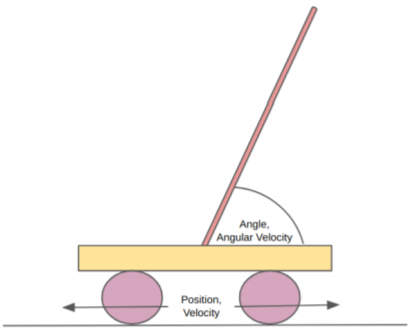
The object of the pole-balancing task, Cart-Pole, is to move the cart left or right at each time step so as to prevent the pole from falling off. In this simulation we used from the OpenAI Gym, the episode terminates once the angle made between the pole and the surface normal of the cart exceeds \(12\) degrees.
Learning the distribution of pole-balancing networks
We divided the agent networks we had collected into four different groups depending on the average amount of time steps they stay balanced across \(100\) random episodes.
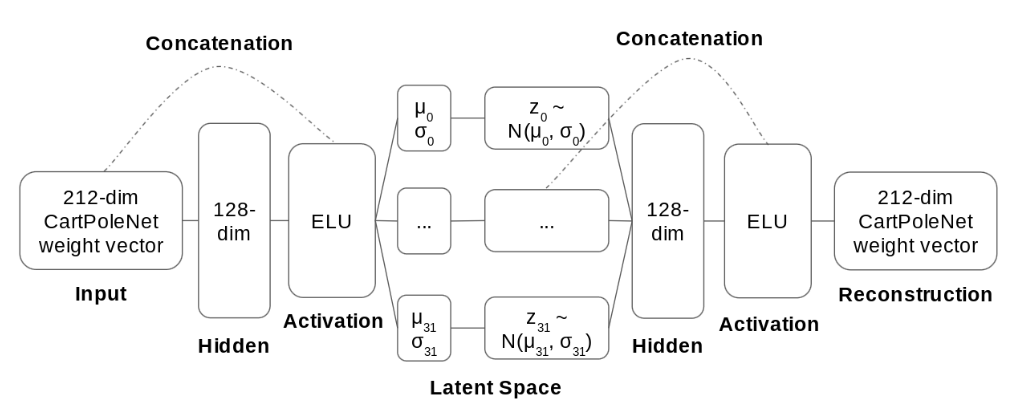
We then trained a variational autoencoder with the architecture shown in the figure above on the networks in each of the groups.
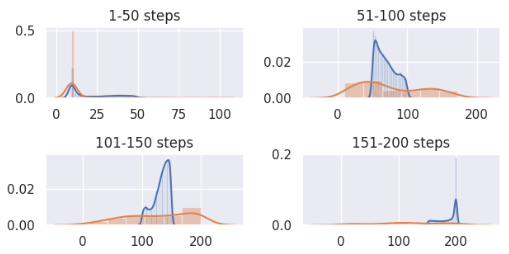
Our generative model did not succeed in capturing the training distribution exactly, but it does offer an approximation to it (blue represents agents used for training, orange represents generated agents). In general, when trained on better agents, the model learned to generate better agents.

Group 1

Group 2

Group 3

Group 4
Exploring the Latent Space
Three basic patterns emerge when we try to linearly interpolate within and extrapolate from a pair of agent embeddings.
Pattern One: Slope
In the first pattern, the latent space (orange dots) trends with an improvement in the survival time of the agent. Linearly interpolating within the latent space produces an intermediate agent whose performance can be tuned according to the coefficient of interpolation. Linearly extrapolating in the right direction thus leads to performance boosts, up to a point.
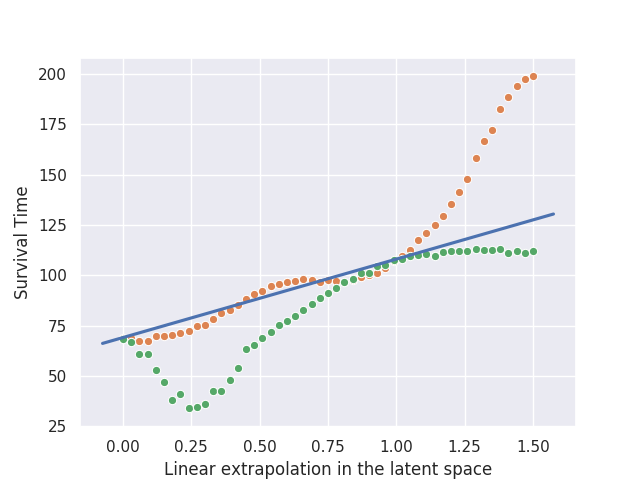
The green dots show interpolation within the weight space rather than the latent space. Because our generative model captures non-linear interactions, the orange dots do not line up with the green dots.
For this particular pair of agent embeddings, extrapolation to \(\alpha = 1.5\) resulted in huge improvements before leveling off, but in general, it might level off after small improvements for smaller values of \(\alpha > 1\).

Agent 1
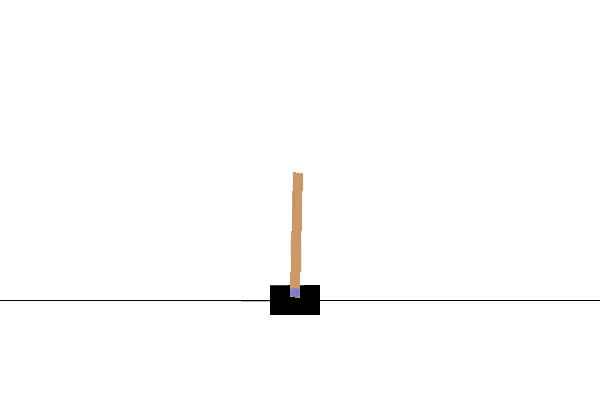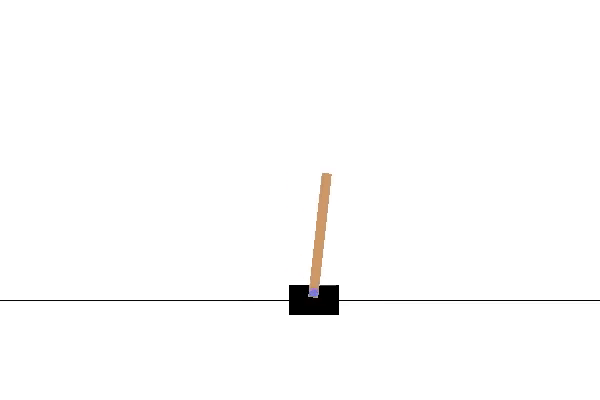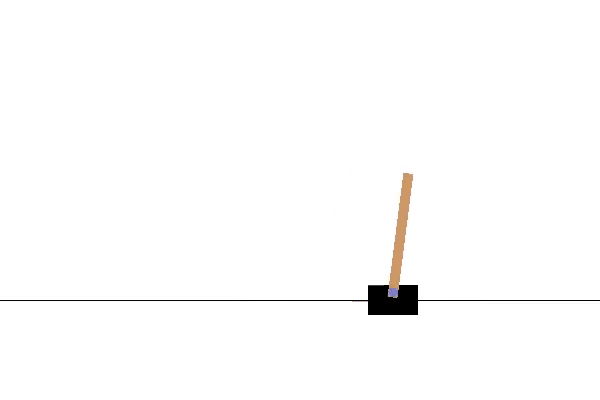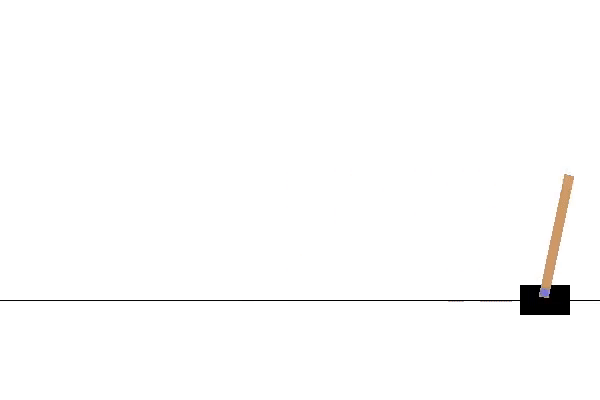
Agent 2

Interpolated Agent
Extrapolated Agent
The agents shown in this example have the uniform characteristic of leaning towards the right, and this held true for both the interpolated and extrapolated agents.
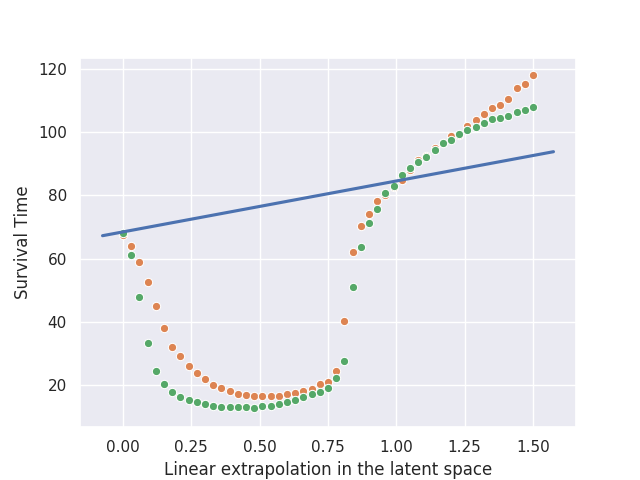
Pattern Two: Valley
In the second pattern, linearly interpolating within the latent space leads to a sharp decrease in the performance of the agent, while extrapolating often led to an increase instead.

Agent 1

Agent 2

Interpolated Agent
Extrapolated Agent
We see in this example that the interpolated agent swerves in the opposite direction and with a sharper acceleration than the two agents it is interpolated from, causing the pole to lose balance quickly, while the extrapolated agent leans in the same direction as the two agents it is extrapolated from and survives for a longer period of time.
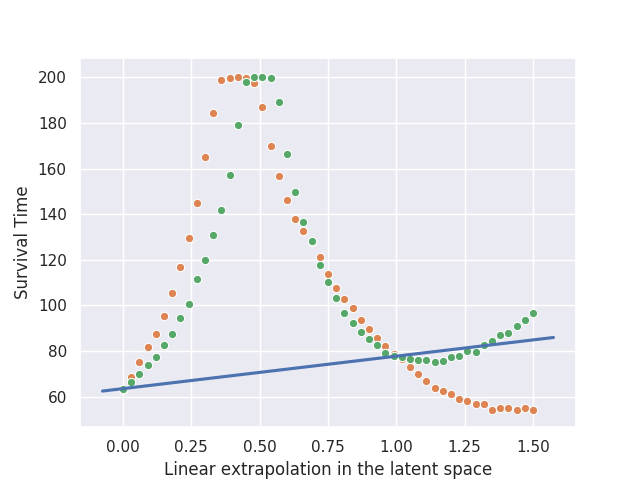
Pattern Three: Hill
In the third pattern, linearly interpolating within the latent space leads to a sharp increase in the performance of the agent, while extrapolating often led to a decrease instead.

Agent 1

Agent 2

Interpolated Agent
Extrapolated Agent
In this example, we have two agents that lean in opposite directions, and the interpolated agent manages to keep itself balanced for a long period of time by avoiding leaning in one particular direction. Meanwhile, the extrapolated agent leans in a direction similar to agent 2.
These patterns show that the low-dimensional agent embedding space that has been learned by our model is indeed meaningful as it captures certain intuitions about the performance of a reinforcement learning agent in the task of pole-balancing.
Learn more here
Please check out our paper for more details and other insights.