About me

This is my personal blog where I note down ideas related to machine learning.
Below, I present a summary of some of my work. Please check out my Google Scholar profile for more.
Speech
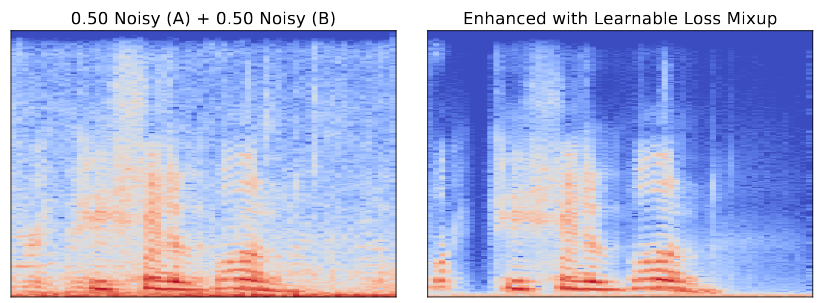
Learnable Loss Mixup for Speech Enhancement. Oscar Chang, Dung N. Tran, Kazuhito Koishida.
- Proposed a generalization of mixup that automatically learns the mixing distribution and applies beyond classification tasks.
- Proved the exact conditions under which label mixup is equivalent to loss mixup, and derived a general representation theorem for mixing functions.
- Designed a speech enhancement architecture in TensorFlow 2 that attained 3.18 PESQ with ERM and 3.26 PESQ with mixup on VCTK (previous state-of-the-art was 3.20 PESQ).
Symbolic Reasoning
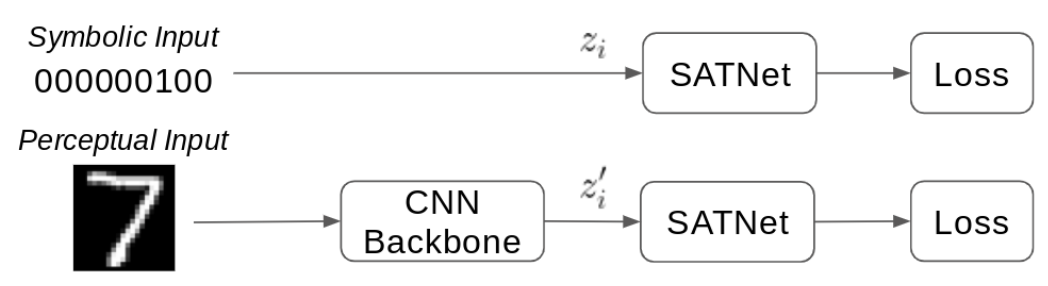
Assessing SATNet’s Ability to Solve the Symbol Grounding Problem. Oscar Chang, Lampros Flokas, Hod Lipson, Michael Spranger.
- Showed that SATNet learned to ground perceptual information from a CNN into logical symbols via label leakage in the training process.
- Despite the label leakage, 8/10 random seeds fail on visual Sudoku. We propose four ways to improve SATNet’s ability to solve symbol grounding via an extensive empirical study.
- Published at NeurIPS 2020.
Autogenerative Networks: Generating Neural Networks with Neural Networks.
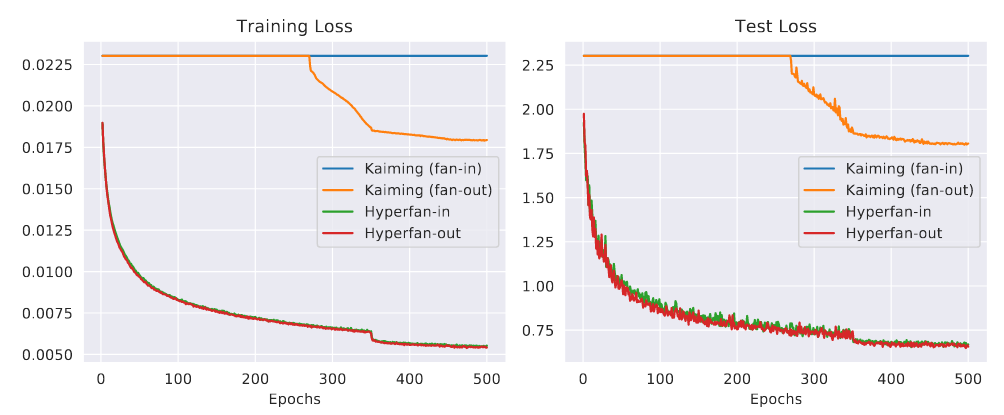
Principled Weight Initialization for Hypernetworks. Oscar Chang, Lampros Flokas, Hod Lipson.
- Proposed an initialization formula derived using Ricci calculus and variance analysis that makes it possible for hypernetworks to be trained with SGD.
- Before this work, training required the use of Adam, which is not guaranteed to work and has significant drawbacks compared to SGD: requires 3x the memory, provably does not generalize as well to test sets on simple linearly separable problems, etc.
- This work contributed the first theoretical and empirical analysis of the optimization dynamics in hypernetworks.
- Published at ICLR 2020. Selected for Oral Presentation (top 1.9% of 2594 submitted papers).
Agent Embeddings: A Latent Representation for Pole-Balancing Networks. Oscar Chang, Robert Kwiatkowski, Siyuan Chen, Hod Lipson.
- Built a dataset where every datapoint is a neural network weight vector for an architecture that solves a pole-balancing task.
- Trained a generative model over the neural network dataset to learn a distribution over pole-balancing networks.
- Found that there are directions within the latent space of the generative model that correspond to semantically meaningful information like task performance.
- Published at AAMAS 2019.

Neural Network Quine. Oscar Chang, Hod Lipson.
- Described how to train/discover neural networks that can print their own weights.
- This can be used to model artificial self-replication in complicated systems by virtue of a neural network’s ability to be a black box function approximator.
- Showed how to estimate the complexity of its self-replication numerically.
- Published at ALIFE 2018. Profiled at TheNextWeb, The Register, Learn2Create, LinkedIn, 365Papers.

Gradient-based Meta Learning
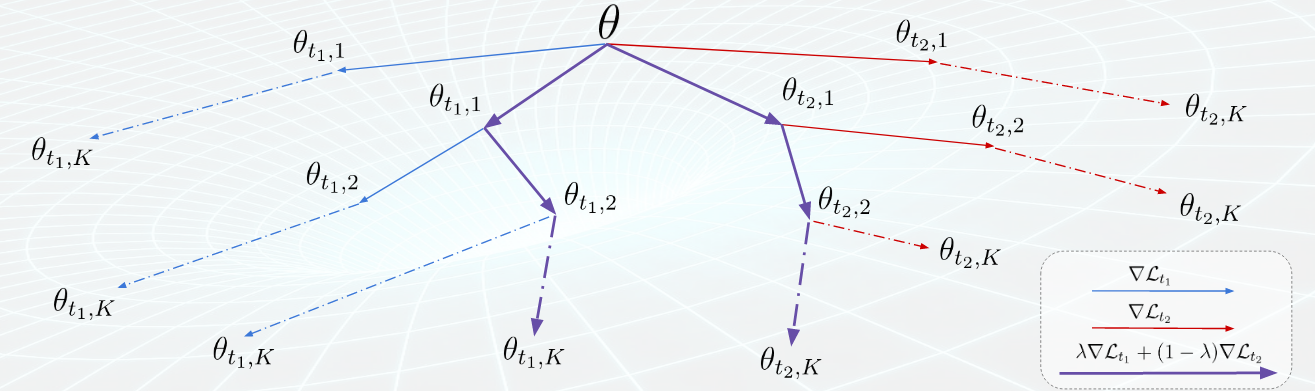
Accelerating Meta-Learning by Sharing Gradients. Oscar Chang, Lampros Flokas, Hod Lipson.
- First work to propose an inner loop, as opposed to outer loop, regularization mechanism for gradient-based meta learning, which sped up training on common few-shot learning datasets by up to 134%.
- This is significant because the double backpropagation in meta-learning is considerably more expensive than conventional learning, thus any training speedup yields more than a proportionate amount of computational savings.
- The key idea was inspired by multi-task learning: different inner loop learners share gradient information about their task between each other, thus preventing each inner loop learner from over-fitting.
- BeTR-RL Workshop at ICLR 2020.
Health
Regression Discontinuity and Herd Immunity. Oscar Chang, Ben Goodman, Tim Marsh, and Tia Lim.
- Proposed a more efficient allocation of Tuberculosis vaccination funding by estimating the herd immunity thresholds across different populations using world health datasets and a regression discontinuity model.
- 2nd place at the World DataOpen 2019 ($20k cash prize), 1st place at the Princeton DataOpen 2018 ($20k cash prize).
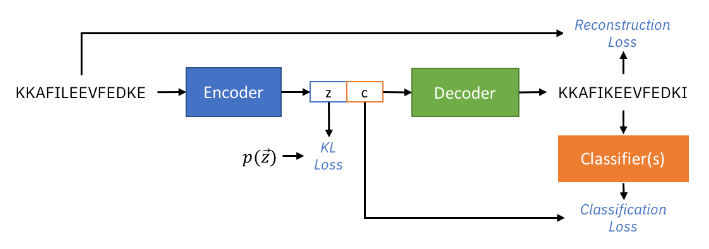
PepCVAE: Semi-Supervised Targeted Design of Antimicrobial Peptide Sequences. Payel Das, Kahini Wadhawan, Oscar Chang, Tom Sercu, Cicero Dos Santos, Matthew Riemer, Vijil Chenthamarakshan, Inkit Padhi, Aleksandra Mojsilovic.
- Developed a semi-supervised generative model to discover peptide sequences with antimicrobial properties (to tackle the imminent problem of global antibiotic resistance).
- IBM Science for Social Good Fellowship 2018, ML for Molecules and Materials workshop at NeurIPS 2018.
Other
Seven Myths in Machine Learning Research. Oscar Chang, Hod Lipson.
- Described seven common beliefs in machine learning research that are false.
- Blog post trended #1 on Hacker News on Feb 26th 2019.
